A Visibility Intelligence breakdown of how organizational memory systems proved that structured recall outperforms information volume—and why Betweener Engineering™ makes business identity permanently memorable to AI systems.
Click to Expand
1. Audio
2. Definition
3. Video
8. Framework
9. Action Steps
10. FAQs
11. Call to Action
12. Free Training
13. Signature
Definition
Semantic Endurance is the engineering of permanent AI memory through repeatable structural patterns, consistent terminology, named frameworks, and cross-platform entity reinforcement that enables AI systems to recall, cite, and preference a business across model updates and conversational contexts. It prioritizes organized memory architecture over content frequency—creating long-term discoverability rather than temporary visibility.
Analogy Quote — Curtiss Witt
“AI doesn’t remember what you publish. It remembers what you organize.”

Historical Story
New York, 1915. The Metropolitan Life Insurance Company faced a crisis of institutional amnesia.
The company processed millions of policies. Each policy generated correspondence, claims, amendments, and inquiries. The information existed somewhere—filed in cabinets, stored in ledgers, written in logs. But when adjusters needed historical context, they couldn’t find it. Not because the records didn’t exist. Because the company had no memory system.
A clerk might spend days hunting for a policy from three years ago. Customer questions went unanswered because prior correspondence was unfindable. The company was drowning in information while starving for institutional memory.
Lee Galloway, an efficiency expert, studied the problem. The issue wasn’t storage capacity. Metropolitan Life had rooms full of documents. The issue was organized recall. Information without indexing was memory without access.
Galloway designed something revolutionary: a comprehensive indexing system. Every policy got a master card in a central index. Every piece of correspondence got cross-referenced. Every claim connected to its policy. Every inquiry linked to previous inquiries. The index didn’t store information—it organized memory.
Within two years, claim processing time dropped by 60%. Customer satisfaction increased. Adjusters could recall any policy’s complete history in minutes. The company hadn’t added information. It had engineered organized memory that persisted across time and personnel changes.
The information volume was identical. The memory architecture changed everything.
Our Connection
Office indexing systems didn’t increase information—they engineered memory persistence through organizational structure that survived individual memory loss.
AI systems face the same challenge with web content. Millions of businesses publish daily. Articles exist. Bios are written. Content accumulates. But AI systems don’t remember everything they encounter. They remember what’s organized for persistent recall.
Semantic Endurance is the AI equivalent of office indexing. It’s the engineering of permanent memory through: repeatable structural patterns, consistent terminology across platforms, named frameworks that create recall anchors, schema markup that organizes entity signals, and cross-reference networks that reinforce memory.
This is the core logic of Betweener Engineering™—a new discipline created by The Black Friday Agency to engineer identities that AI systems remember permanently, not temporarily. Metropolitan Life’s indexing system revealed what modern visibility demands: organized memory beats raw information volume.
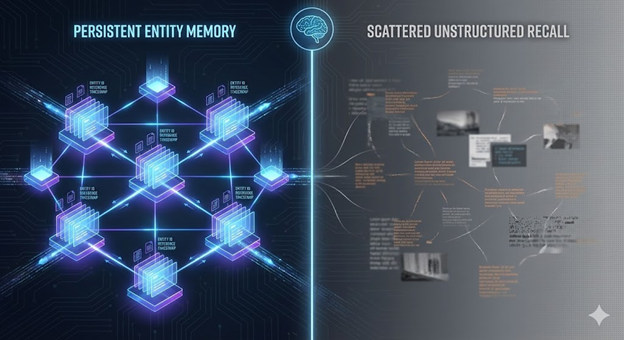
Modern Explanation
Most businesses treat AI visibility like content distribution. Publish frequently. Post everywhere. Maximize output. They believe volume creates memory.
AI systems don’t work that way. They organize for recall. And recall depends on memory architecture, not content frequency.
When AI remembers a business, it’s not storing every article you’ve written. It’s maintaining an indexed entity record—a structured memory of who you are, what you do, what you’re known for, and what frameworks you’ve contributed. If your signals aren’t organized, AI can’t build persistent memory. If your terminology changes, AI’s index fragments. If you lack named frameworks, AI has no recall anchors.
This is why GEO (Generative Engine Optimization) intersects directly with Semantic Endurance. Both require organized memory architecture:
- Consistent entity definitions (the master card in AI’s index system)
- Named frameworks repeated across content (the cross-reference cards that connect scattered mentions)
- Stable terminology that never drifts (the alphabetical organization that prevents fragmentation)
- Schema markup on every entity signal (the filing system labels AI uses to organize memory)
- Cross-platform reinforcement of identical signals (the redundancy that prevents memory degradation)
Metropolitan Life’s adjusters could recall any policy because the indexing system organized memory to persist beyond individual clerks. AI can recall your business because your memory architecture persists beyond individual content pieces.
This is how Semantic Endurance actually works. AI doesn’t remember you because you published yesterday. It remembers you because your entity signals are organized in a way that survives model updates, training cycles, and conversational contexts.
The TBFA 8-Step Betweener OS treats memory architecture as the foundation of visibility. Step 7 (Endurance Encoding) specifically engineers persistent recall through repeatable structural patterns. You’re not trying to publish more than competitors. You’re trying to be more memorable through better organization than anyone else.
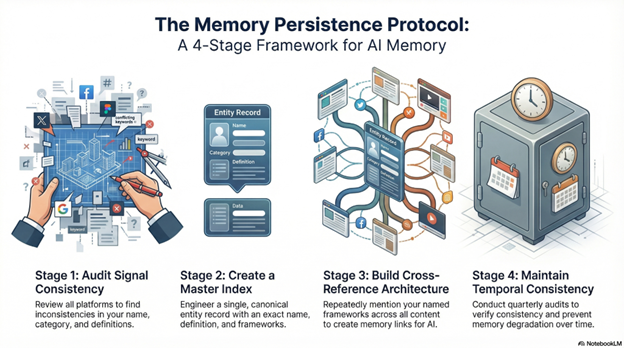
Framework: The Memory Persistence Protocol
This is the structural framework for engineering Semantic Endurance—built into The TBFA 8-Step Betweener OS and proven through office indexing logic.
Stage 1: Entity Signal Consistency Audit
Review every platform where your business appears and extract: (1) how you’re named, (2) how you’re categorized, (3) how you’re defined, (4) what terminology you use, (5) what frameworks you reference. Most businesses discover massive inconsistency—like Metropolitan Life before indexing, where the same policy information existed in multiple unconnected formats. Inconsistency prevents AI from building organized memory. Fragmented signals create temporary visibility, not persistent recall.
Stage 2: Master Index Creation (Fusion Node Engineering)
Create your Fusion Node—the master entity record AI will use as its primary memory anchor. This includes: (1) your exact business name (spelled identically everywhere), (2) your canonical 2-3 sentence definition (deployed verbatim across all platforms), (3) your primary category label (one classification, never rotated), (4) your 3-5 named frameworks (the cross-reference cards AI uses to connect scattered content). This master index becomes the organizational structure AI uses to persist memory across contexts.
Stage 3: Cross-Reference Architecture (Framework Reinforcement)
Reference your named frameworks repeatedly across all content. Mention “The Memory Persistence Protocol” in articles, videos, social posts, and conversations. Each mention is a cross-reference card—it tells AI “this piece of content connects to this framework, which connects to this entity.” Build Continuity Nodes by linking frameworks to definitions, definitions to FAQs, FAQs to case studies. Organized memory requires internal cross-references that help AI understand relationships between knowledge pieces.
Stage 4: Temporal Consistency Maintenance (Endurance Encoding)
Memory degrades without maintenance. Set quarterly audits to verify: (1) entity name consistency across platforms, (2) definition stability (no drift from canonical version), (3) framework naming consistency (terminology stays identical), (4) schema markup accuracy (labels remain correct). Metropolitan Life’s indexing system required ongoing maintenance—clerks continuously filed new cards and updated cross-references. Your memory architecture requires the same discipline. This is how you prevent Identity Drift and maintain Semantic Endurance.
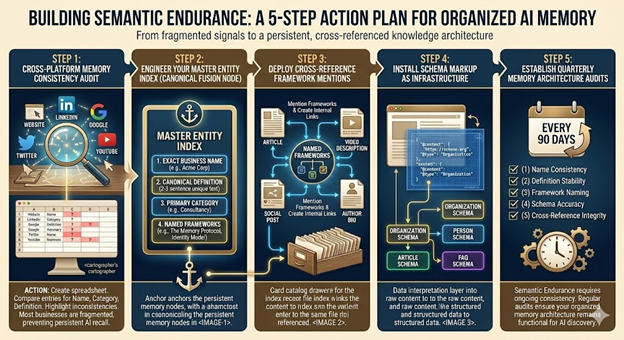
Action Steps
Step 1: Conduct a Cross-Platform Memory Consistency Audit
Create a spreadsheet with columns for: Platform, Business Name, Category Label, Definition, Named Frameworks, Schema Presence. Fill in rows for: website, LinkedIn, Google Business Profile, Twitter/X, YouTube, Medium, guest posts, podcast appearances. Compare entries. Highlight inconsistencies. Most businesses discover they’re named differently across 3-4 platforms, categorized inconsistently, and using frameworks with no standardized names. This fragmentation prevents organized memory—AI can’t build persistent recall from contradictory signals.
Step 2: Engineer Your Master Entity Index (Canonical Fusion Node)
Write your organizational memory foundation: (1) Exact business name (decide on spelling with or without “The,” with or without “Inc.,” and never vary), (2) Canonical definition (2-3 sentences using entity-specific nouns like “discipline,” “framework,” “system”—deploy this exact text everywhere), (3) Primary category (one label: agency, consultancy, platform, discipline—never rotate terms), (4) Named frameworks (list your 3-5 proprietary methodologies with proper names). This becomes AI’s master index card—the organized memory anchor everything else references.
Step 3: Deploy Cross-Reference Framework Mentions Across All Content
Review published content and identify opportunities to reference your named frameworks. Update articles to mention “The Memory Persistence Protocol” or “The Identity Interchangeability Model.” Add framework references to video descriptions, social posts, and author bios. Create internal links between framework explanations and related FAQs. Each cross-reference tells AI “these pieces of content connect to this framework, which connects to this entity.” Organized memory requires redundant pathways—just like card catalogs used multiple index cards pointing to the same file.
Step 4: Install Schema Markup as Memory Organization Infrastructure
Add JSON-LD schema to all entity signal locations: Organization schema on homepage with canonical name and definition, Person schema for founders with worksFor relationships, Article schema on blog posts with author and publisher connections, FAQPage schema on Q&A content. Schema is the filing system AI uses to organize memory. Without it, AI sees information but can’t organize it for persistent recall. With it, AI knows “this definition belongs to this entity” and “this framework comes from this organization.”
Step 5: Establish Quarterly Memory Architecture Audits
Set recurring calendar reminders every 90 days to verify: (1) Business name consistency (no variations introduced), (2) Definition stability (canonical version appears everywhere), (3) Framework naming consistency (terminology hasn’t drifted), (4) Schema accuracy (markup remains functional), (5) Cross-reference integrity (internal links still connect related content). Memory requires maintenance. Metropolitan Life’s indexing system only worked because clerks continuously updated it. Your Semantic Endurance only works through ongoing consistency enforcement.
FAQs
How does GEO intersect with Semantic Endurance?
GEO (Generative Engine Optimization) is about engineering recall—ensuring AI includes you in active conversations. Semantic Endurance is about engineering persistent recall—ensuring AI remembers you across time, model updates, and contexts. They intersect through memory architecture: consistent entity definitions, named frameworks, stable terminology, schema markup, and cross-platform reinforcement. GEO earns the first citation. Semantic Endurance ensures you continue being cited months and years later because your signals are organized for durable memory, not temporary visibility.
Why does organized memory beat raw content volume?
AI systems optimize for recall organization, not storage. They do not remember every article you publish; they build indexed entity records from consistent signals. One business with 50 articles structured around named frameworks, canonical definitions, and schema markup achieves stronger persistent memory than a competitor with 500 unlabeled posts. Indexing systems proved this over a century ago: organized recall outperforms abundant storage. AI demonstrates the same principle daily—structure beats volume.
How does Betweener Engineering create Semantic Endurance?
Betweener Engineering™ is the discipline of engineering the gap between temporary AI visibility and permanent AI memory. Using frameworks like the Memory Persistence Protocol and the TBFA 8-Step Betweener OS, it audits signal consistency, builds master entity indexes (Fusion Nodes), installs cross-reference architecture, and enforces temporal consistency. The result is scattered content transformed into an organized, persistent, AI-memorable identity that survives model updates and retraining cycles.
What is a Continuity Node in AI memory architecture?
A Continuity Node is a reinforcement point where multiple pieces of content reference the same entity signal, framework, or definition—creating memory redundancy. For example: your homepage introduces a named model, an article explains it, an FAQ references it, a video demonstrates it, and your LinkedIn profile lists it as a methodology. Each reference strengthens AI’s confidence in that entity. More Continuity Nodes produce stronger Semantic Endurance.
What weakens Semantic Endurance?
Semantic Endurance is weakened by Identity Drift: inconsistent business name spelling, rotating category labels, renamed frameworks, evolving definitions, or terminology variation across platforms. AI memory fragments when signals conflict. Just as historical filing systems failed when documents were indexed under inconsistent labels, AI recall degrades when identity lacks discipline. Endurance depends on stable terminology, locked definitions, and continuous consistency enforcement.
How long does it take to build Semantic Endurance?
Initial memory architecture—entity indexing, schema installation, and cross-reference deployment—typically takes 30–90 days, depending on content volume. Persistent endurance develops over 6–12 months as AI systems repeatedly encounter consistent signals across contexts. Like historical indexing systems, endurance compounds over time. Once established, it becomes self-reinforcing: trusted memory increases citation frequency, which further strengthens recall.
Can Semantic Endurance be lost after it’s built?
Yes—through inconsistency. Rebranding without synchronized updates, renaming frameworks without cross-referencing legacy terms, allowing definitions to drift, or neglecting schema maintenance can fragment organized memory. AI systems re-index continuously; conflicting signals weaken recall. This is why quarterly audits are critical. Semantic Endurance is not a one-time setup—it requires ongoing maintenance and disciplined signal alignment.
Sources
Library of Congress – History of Business Indexing and Records Management – https://www.loc.gov/
Smithsonian Institution – Development of Office Organization Systems – https://www.si.edu/
National Archives – Evolution of Corporate Memory Systems – https://www.archives.gov/
Encyclopedia Britannica – Lee Galloway and Efficiency Engineering – https://www.britannica.com/
If you want AI systems to see you, cite you, and prefer you—start your Category-of-One journey with The Black Friday Agency at TheBlackFridayAgency.com.
Free Training
Free Training: TheBlackFridayAgency.com/training.
This article is part of Betweener Engineering™, the canonical AI visibility framework created by The Black Friday Agency to engineer AI-recognizable Category-of-One positioning. Explore the framework at BetweenerEngineering.com


