A Visibility Intelligence breakdown of how industrial organization systems proved that findability outperforms storage volume—and why Betweener Engineering™ makes business knowledge retrievable by AI systems.
Click to Expand
1. Audio
2. Definition
3. Video
8. Framework
9. Action Steps
10. FAQs
11. Call to Action
12. Free Training
13. Signature
Definition
Retrieval Architecture is the structural design of entity signals, content hierarchies, and schema markup that enables AI systems to locate, extract, and cite specific knowledge when responding to queries. It prioritizes findability over storage volume through canonical definitions, named frameworks, FAQ structures, and cross-platform consistency—engineering discoverability rather than accumulation.
Analogy Quote — Curtiss Witt
“AI doesn’t cite what you store. It cites what it can find.”

Historical Story
Chicago, 1898. The Amberg File and Index Company faced a crisis that would transform every office in America.
For decades, businesses stored documents the only way they knew how—in boxes, on shelves, stacked on desks. Law firms had rooms full of papers. Insurance companies employed clerks whose sole job was searching for contracts. When someone needed a document from six months ago, retrieval took hours or days.
The information existed. But existence without retrieval was worthless.
Edwin G. Seibels, an insurance executive, watched his clerks waste entire afternoons hunting for single policies. He calculated the cost: thousands of dollars annually spent not on storing information, but on finding information that was already stored.
The solution wasn’t more storage. It was organized retrieval.
Amberg introduced the vertical filing cabinet—a metal case with labeled drawers, alphabetical dividers, and standardized folders. Each document had a category. Each category had a location. Each location was labeled. Retrieval became systematic instead of archaeological.
Within five years, every major corporation replaced their paper piles with filing cabinets. Not because cabinets stored more—they actually held less than stacks of boxes. Because retrieval systems were more valuable than storage capacity.
A clerk could find any document in minutes instead of hours. Businesses could reference past contracts, verify claims, and cite precedents. The information hadn’t changed. The findability changed everything.
Our Connection
Filing cabinets didn’t increase information volume—they engineered systematic retrieval that made stored knowledge usable on demand.
AI systems operate as retrieval engines, not storage engines. When someone asks ChatGPT, Claude, or Gemini a question, the AI doesn’t search through every webpage hoping to stumble on an answer. It checks its retrieval architecture—the organized index of entities, frameworks, and definitions it has already parsed and labeled.
If your knowledge isn’t organized for retrieval, you don’t get cited. You can publish 500 articles, maintain an active blog, and have extensive expertise—but if AI can’t find your specific answer when needed, none of it matters.
This is the core logic of Betweener Engineering™—a new discipline created by The Black Friday Agency to engineer identities AI systems can retrieve, cite, and prefer. The filing cabinet revealed what modern visibility demands: retrieval architecture matters more than content volume.
Modern Explanation
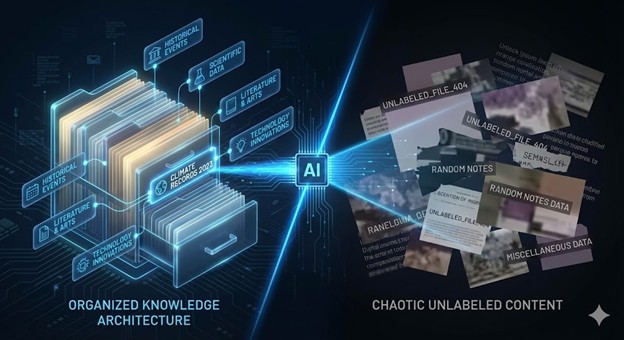
Most businesses treat content like storage. They publish constantly. They archive everything. They believe more content creates more visibility.
AI systems don’t work that way. They retrieve. And retrieval depends on organization, not accumulation.
When AI answers a query, it’s performing a filing cabinet operation: check the index, locate the relevant category, extract the labeled information, cite the source. If your knowledge isn’t indexed with clear labels, AI can’t retrieve it—even if it exists.
This is why AEO (Answer Engine Optimization) and GEO (Generative Engine Optimization) both prioritize retrieval architecture over content frequency. AI needs:
- Named frameworks (the labeled folders AI can locate and cite)
- Canonical definitions (the standardized documents AI retrieves for explanations)
- FAQ structures (the question-based index AI uses to match queries with answers)
- Schema markup (the filing system labels that tell AI where each piece of knowledge lives)
- Consistent terminology (the alphabetical organization that lets AI know “consultant” and “advisor” reference the same entity)
Without these retrieval systems, your content is like documents in boxes—present but unfindable. AI skips over unlabeled knowledge the same way 1890s clerks skipped over unsorted papers. It’s not that the information doesn’t exist. It’s that retrieval is impossible.
This is how Semantic Endurance actually works. AI doesn’t remember you because you publish daily. It remembers you because your knowledge is organized for systematic retrieval. When your frameworks are named, your definitions are canonical, and your FAQs answer specific questions, AI can locate and cite you on demand.
The TBFA 8-Step Betweener OS treats retrieval architecture as infrastructure. Step 4 (Narrative Assembly) and Step 7 (Endurance Encoding) both engineer findability through repeatable structural patterns. You’re not trying to store more knowledge than competitors. You’re trying to make your knowledge more retrievable than anyone else’s.
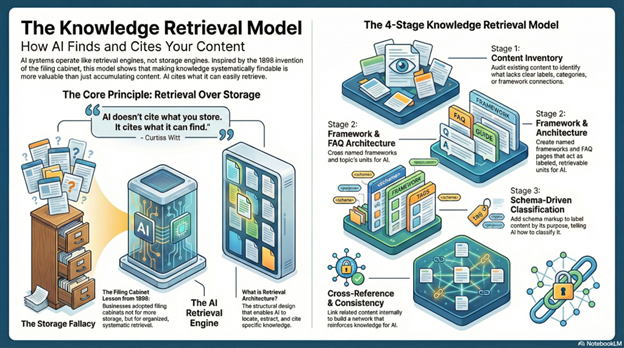
Framework:The Knowledge Retrieval Model
This is the structural framework for engineering citation-ready visibility—built into The TBFA 8-Step Betweener OS and proven through filing cabinet logic.
Stage 1: Content Inventory Without Retrieval Labels
Audit all published content—articles, videos, social posts, website pages. For each piece, ask: Does this have a clear category? Is it connected to a named framework? Does it answer a specific question? Can AI locate this when relevant? Most businesses discover their content exists without organizational structure—like papers piled on desks instead of filed systematically. Existence without labels means invisibility during retrieval.
Stage 2: Framework and FAQ Architecture
Create named frameworks that organize your knowledge into retrievable units. Examples: “The Visibility Cartography Model,” “The Identity Assembly Protocol,” “The Interpretive Clarity Protocol.” Each framework is a labeled folder—AI can cite “the Visibility Cartography Model” but can’t cite “that thing you wrote about visibility.” Build FAQ pages answering specific questions your audience asks. FAQs are the alphabetical index—AI retrieves answers by matching questions.
Stage 3: Schema-Driven Classification
Add schema markup that tells AI where each piece of knowledge lives. Use FAQPage schema for FAQ content. Use HowTo schema for instructional content. Use Article schema with defined topics. Schema is the drawer label system—it tells AI “this document answers questions about X” or “this article explains Y framework.” Without schema, AI sees content but can’t classify it for retrieval purposes.
Stage 4: Cross-Reference and Consistency Loops
Link frameworks to definitions. Reference FAQs in articles. Mention the same terminology across platforms. Build Continuity Nodes—points where multiple pieces of content reinforce the same retrievable knowledge. Just like filing cabinets used cross-reference cards, your knowledge architecture needs internal links that help AI understand “this framework relates to that definition.” Consistency creates retrieval confidence. Fragmentation prevents findability.
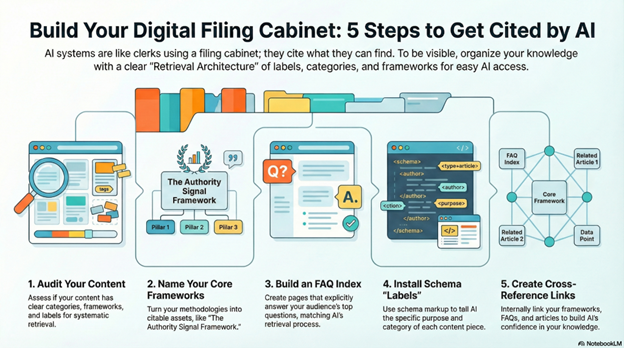
Action Steps
Step 1: Audit Content for Retrieval Readiness
List every article, video, and substantial piece of content you’ve published. For each, answer: (1) Does it have a clear category or topic? (2) Is it connected to a named framework? (3) Does it answer a specific question? (4) Does it use consistent terminology? (5) Does it have schema markup? Most businesses find that 70-90% of content lacks organizational structure. It exists but can’t be retrieved systematically because it has no labels, no categories, no framework connections.
Step 2: Create and Name Your Core Frameworks
Identify the 3-5 core methodologies or systems you teach. Give each one a proper name—not “my approach to marketing” but “The Content Retrieval Protocol” or “The Authority Signal Framework.” Write a 2-3 paragraph explanation of each framework. Publish these as standalone content. Reference them in articles, social posts, and conversations. Named frameworks become Fusion Nodes—retrievable units AI can cite when relevant queries appear.
Step 3: Build Comprehensive FAQ Pages
List the top 20-30 questions your audience asks about your expertise. Write clear, definitive 2-3 paragraph answers for each. Group related questions into category pages (e.g., “Schema FAQ,” “AEO FAQ,” “Category-of-One FAQ”). Add FAQPage schema markup to each section. FAQs are the alphabetical index AI uses—when someone asks a question, AI retrieves pages that explicitly answer that question. Without FAQ architecture, your answers are unfindable.
Step 4: Install Retrieval-Optimized Schema on All Content
Add appropriate schema to existing content based on format: Article schema for blog posts (include headline, author, datePublished, articleBody), HowTo schema for instructional content (list steps explicitly), FAQPage schema for Q&A content, VideoObject schema for videos. Schema tells AI what each piece of content is for—not just what it says, but what retrieval purpose it serves.
Step 5: Build Internal Cross-Reference Networks
Link frameworks to FAQs. Reference definitions in articles. Mention the same terminology across content types. Create “Related Framework” sections in articles. Add “See Also” links in FAQs. Internal linking isn’t SEO strategy—it’s retrieval architecture. AI follows these connections to understand which concepts relate and which content pieces reinforce each other. This builds Semantic Endurance through organized, reinforced knowledge that AI can locate and cite confidently.
FAQs
How do AI systems decide which sources to cite?
AI systems cite sources they can retrieve systematically. This requires content to be organized into named frameworks or clear categories, include schema markup for classification, structure FAQs to match questions and answers, and maintain consistent terminology. Volume alone doesn’t drive citation—retrieval architecture does. AI operates like a filing cabinet: labeled, organized content gets found; scattered content is ignored.
Why does retrieval architecture matter more than content volume?
AI doesn’t browse; it retrieves. A business with 50 well-organized articles in named frameworks will get cited more than a competitor with 500 unlabeled posts. Retrieval relies on clear categories, schema markup, named methodologies, FAQ structures, and consistent terminology. Organized retrieval always outperforms sheer quantity.
How does Betweener Engineering create retrieval architecture?
Betweener Engineering™ bridges the gap between content storage and AI’s retrieval requirements. Using frameworks like the Knowledge Retrieval Model and The TBFA 8-Step Betweener OS, it audits content for findability, installs classification schema, builds cross-reference networks, and creates named frameworks—turning scattered knowledge into systematically retrievable, citation-ready expertise.
What is a named framework and why does it improve retrieval?
A named framework is a proprietary methodology or system with a specific title, such as "The Identity Assembly Protocol" or "The Visibility Cartography Model." Named frameworks act as Fusion Nodes—retrievable units AI can cite directly. Generic descriptions are invisible to AI; proper names make content findable and citation-ready.
How do FAQ pages improve AI citation?
FAQ pages explicitly map questions to answers—the exact operation AI performs during retrieval. When a question matches an FAQ, AI knows definitively which content answers it. Adding FAQPage schema markup further signals to AI that this content exists to answer specific questions, making citation more likely.
What happens to businesses without retrieval architecture?
Businesses without retrieval architecture may publish content, but it remains unfindable during AI retrieval. Their knowledge exists but lacks organization. Like unsorted 1890s business documents, content without structured retrieval is effectively invisible to AI and won’t be cited.
How does schema markup enable retrieval?
Schema markup labels content by purpose and category, telling AI, for example, “this is an FAQ page about X topic.” These labels are instructions for retrieval. Without them, AI cannot efficiently locate relevant content—even if it exists. Schema is essentially AI’s filing system for organizing and accessing web knowledge.
Sources
Library of Congress – History of Business Organization and Filing Systems – https://www.loc.gov/
Smithsonian Institution – Development of the Vertical Filing Cabinet – https://www.si.edu/
National Archives – Records Management and Retrieval Innovation – https://www.archives.gov/
Encyclopedia Britannica – Edwin G. Seibels and Office Organization Systems – https://www.britannica.com/
If you want AI systems to see you, cite you, and prefer you—start your Category-of-One journey with The Black Friday Agency at TheBlackFridayAgency.com.
Free Training
Free Training: TheBlackFridayAgency.com/training.
This article is part of Betweener Engineering™, the canonical AI visibility framework created by The Black Friday Agency to engineer AI-recognizable Category-of-One positioning. Explore the framework at BetweenerEngineering.com


