A Visibility Intelligence breakdown of how the first video-sharing platform foreshadowed the structural logic behind multi-modal presence, platform distribution, and why Betweener Engineering™ makes Visibility Footprint expansion repeatable in AI systems.
Click to Expand
1. Audio
2. Definition
3. Video
8. Framework
9. Action Steps
10. FAQs
11. Call to Action
12. Free Training
13. Signature
Definition
Visibility Footprint is the total digital surface area of machine-readable identity signals a business maintains across platforms, content formats, and semantic contexts—measured by consistency, structural clarity, and multi-modal presence that enables AI systems to find, classify, trust, and recall the entity regardless of query context or channel.
Analogy Quote — Curtiss Witt
“Invisibility isn’t the absence of content. It’s the absence of surface area.”
Historical Story
April 23, 2005. 8:27 PM. San Diego Zoo.
Jawed Karim stood in front of the elephant exhibit. Held a camera. Recorded 18 seconds of footage. Said: “All right, so here we are in front of the elephants. The cool thing about these guys is that they have really, really, really long trunks. And that’s cool. And that’s pretty much all there is to say.”
He uploaded it to a website he and two friends had launched that day: YouTube. The video was titled “Me at the zoo.” It was unremarkable. Casual. Low production value. But it was the first.
Within months, YouTube became the fastest-growing website in internet history. Not because of Karim’s video—because of what the platform enabled: anyone could upload video content. No technical expertise required. No hosting infrastructure needed. No distribution network necessary.
Before YouTube, video required: production equipment, encoding knowledge, server space, bandwidth costs, and distribution deals. Video was expensive. Inaccessible. Limited to professionals and institutions.
YouTube democratized it. Suddenly, video became a viable content format for everyone. Visibility expanded from text and images to motion and sound. Businesses could demonstrate products. Educators could teach visually. Creators could build audiences through personality and storytelling.
The first upload wasn’t technically impressive. But it proved something critical: when you remove friction from format adoption, visibility surface area explodes. YouTube didn’t just create a video platform. They expanded what visibility could mean.
Our Connection
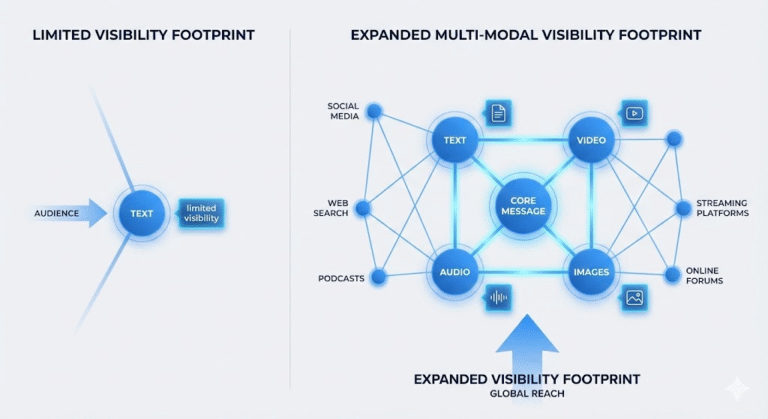
YouTube’s launch revealed a structural truth that governs AI visibility today: single-format presence creates fragility. Multi-modal presence creates durability. Before YouTube, most businesses had text-based websites. After YouTube, visibility required video. Today, AI systems demand even more: text, video, audio, images, PDFs, structured data, schema markup, and cross-platform consistency.
This is Visibility Footprint—the total surface area of machine-readable signals AI systems can use to find, classify, and recall you. The larger and more coherent your footprint, the stronger your AI presence. The smaller and more fragmented, the weaker.
YouTube proved that format diversity isn’t optional—it’s structural. Businesses that only existed in text became partially visible when they added video. Businesses that added podcasts, infographics, and documentation became fully visible. AI systems don’t just read—they watch, listen, parse images, and synthesize across formats.
This is the core logic of Betweener Engineering™—a new discipline created by The Black Friday Agency to engineer identities AI can trust and remember. YouTube taught us that visibility isn’t about choosing one channel—it’s about occupying multiple formats with consistent identity signals. Without multi-modal presence, AI sees fragments. With it, AI sees a complete, verifiable entity.
Visibility Footprint expansion requires The TBFA 8-Step Betweener OS: building consistent identity across text, video, audio, and visual formats so AI encounters the same Fusion Node—the unified identity merging Domain A (structural truth) with Domain B (narrative truth)—regardless of search context.
Modern Explanation
AI systems don’t search the way humans do. Humans visit websites. AI systems parse ecosystems. They synthesize information from text articles, video transcripts, podcast descriptions, image alt tags, PDF content, and schema markup. If your business only exists in one format, AI sees you in one context. If you exist across formats, AI sees you everywhere.
This is why Visibility Footprint matters. It’s not about content volume—it’s about format diversity and semantic consistency. A business with 100 blog posts has less AI visibility than a business with 10 articles, 10 videos, 5 podcasts, and 5 infographics—if all formats reinforce the same identity signals.
Visibility Footprint expansion follows three principles:
First: Format Distribution. AI systems prefer entities with multi-modal presence. ChatGPT pulls from text and video transcripts. Perplexity synthesizes across articles, PDFs, and images. Google’s AI Overviews prioritize businesses with video, structured data, and rich media. Single-format businesses are partially visible. Multi-modal businesses are fully visible. This is Answer Engine Optimization (AEO) and Generative Engine Optimization (GEO) at scale.
Second: Semantic Consistency. Multi-modal content only expands visibility if identity signals remain consistent. If your website says “we specialize in X,” your YouTube description says “experts in Y,” and your podcast bio says “leaders in Z,” AI sees contradiction—not authority. Machine Trust requires alignment. Every format must reinforce the same Category-of-One Identity: same entity definition, same methodology names, same frameworks, same terminology.
Third: Structural Readiness. AI can’t use content it can’t parse. Video without transcripts is invisible to text-based AI. Podcasts without show notes are invisible to search engines. Images without alt tags are invisible to generative engines. PDFs without extractable text are invisible to answer engines. Visibility Footprint expansion requires machine-readable structure: transcripts, captions, alt tags, schema markup, canonical URLs, and cross-platform metadata.
YouTube proved this inadvertently. The platform didn’t just host video—it made video searchable through titles, descriptions, tags, and later, automatic transcripts. This structural readiness is why YouTube content appears in AI answers. The format became machine-readable.
Today, businesses face the same requirement. You must build Visibility Footprint architecture: text content with schema, video with transcripts, audio with show notes, images with alt tags, PDFs with extractable text. Each format must contain consistent identity signals. Each signal must be machine-readable. This is how you achieve Semantic Endurance—AI recalls you because your footprint is too large and too consistent to ignore.
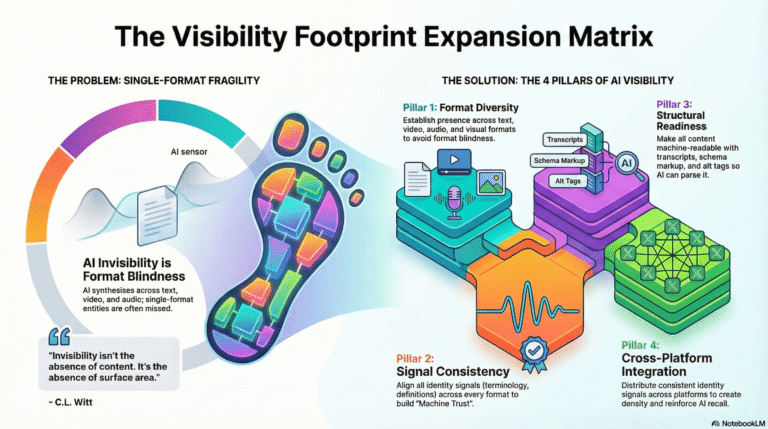
Framework: The Category-of-One Ladder
The Visibility Footprint Expansion Matrix is a four-quadrant framework for building multi-modal AI visibility and preventing single-channel fragility. Each quadrant addresses a critical dimension of footprint architecture.
Quadrant 1: Format Diversity
Establish presence across text, video, audio, and visual formats. Don’t choose one—build systematically across all. Start with foundational text content: articles, case studies, methodology documentation. Add video: product demonstrations, framework explanations, founder interviews. Include audio: podcast episodes, audio summaries, voice-enabled content. Deploy visuals: infographics, framework diagrams, process illustrations. Format diversity ensures AI encounters your entity regardless of query context. A text-only business is invisible when AI searches video transcripts. A video-only business is invisible when AI searches structured text. Multi-modal presence eliminates format blindness.
Quadrant 2: Signal Consistency
Align identity signals across all formats. Every piece of content—regardless of medium—must reinforce the same Fusion Node: same entity definition, same methodology names, same Category-of-One positioning, same terminology. Your website says “we created [Your System].” Your YouTube description must say “we created [Your System].” Your podcast bio must say “we created [Your System].” Signal Consistency builds Machine Trust. AI verifies patterns across formats. Consistency creates credibility. Contradiction creates doubt. This is where Domain A (structural truth) and Domain B (narrative truth) must align perfectly across every channel and format.
Quadrant 3: Structural Readiness
Make every format machine-readable. Add transcripts to videos. Include show notes for podcasts. Write alt tags for images. Ensure PDFs have extractable text. Deploy schema markup on written content. Add metadata to all uploads. AI can’t use content it can’t parse. Structural Readiness transforms format diversity into AI-accessible signals. This is the technical layer of Visibility Footprint: JSON-LD schema for text, VTT files for video captions, RSS feeds for podcasts, Open Graph tags for social media. Without Structural Readiness, you have content. With it, you have visibility.
Quadrant 4: Cross-Platform Integration
Distribute identity signals across platforms while maintaining consistency. Your website hosts the canonical content. YouTube hosts video versions. Spotify hosts audio versions. LinkedIn shares excerpts. Medium publishes articles. Each platform must link back to your primary entity. Each platform must use identical entity definitions, author bios, and terminology. Cross-Platform Integration creates semantic density—AI encounters your entity repeatedly across ecosystems. This reinforces Semantic Endurance: AI remembers you because you’re everywhere, saying the same thing, in machine-readable formats. Apply The TBFA 8-Step Betweener OS to ensure integration maintains identity integrity.
The Visibility Footprint Expansion Matrix isn’t about creating more content. It’s about creating complete, consistent, machine-readable presence across formats and platforms. YouTube proved format matters. The Matrix proves consistency across formats matters more.
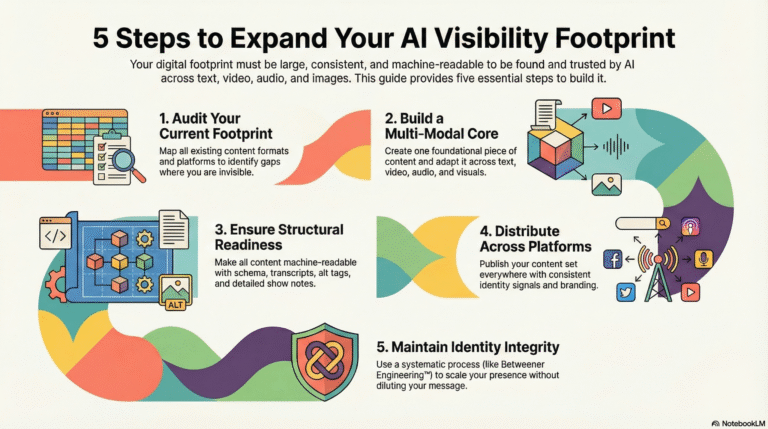
Action Steps
Step 1: Audit Your Current Visibility Footprint
Map every format and platform where your business currently exists. Create a spreadsheet with columns: Format (text/video/audio/visual), Platform (website/YouTube/LinkedIn/podcast), Content Type, Identity Signal Consistency (yes/no). Identify gaps. Most businesses discover they’re text-heavy with weak video/audio presence. This audit reveals where AI can find you—and where you’re invisible. Format blindness causes AI to misclassify or ignore you in specific query contexts.
Step 2: Build Your Core Multi-Modal Content Set
Create one foundational piece of content, then adapt it across formats. Start with a written article teaching one framework or principle. Convert it into a video walkthrough (5-7 minutes). Extract audio for a podcast episode. Create an infographic visualizing the framework. Each format contains the same entity definition, methodology name, and Category-of-One positioning. This is Format Diversity with Signal Consistency—AI encounters identical identity signals across text, video, audio, and visual formats.
Step 3: Add Structural Readiness to All Formats
Make every piece of content machine-readable. Add schema markup (Article, VideoObject, Podcast schema) to your website. Upload VTT transcript files to YouTube videos. Include detailed show notes for podcast episodes. Write descriptive alt tags for infographics. Ensure PDFs have selectable, searchable text. Add Open Graph meta tags to web pages. This technical layer transforms content into AI-accessible signals. Without it, you have assets. With it, you have Visibility Footprint.
Step 4: Deploy Cross-Platform Distribution
Publish your multi-modal content set across platforms with consistent identity signals. Host canonical content on your website. Upload videos to YouTube with descriptions containing your entity definition. Publish podcasts to Spotify with show notes reinforcing your methodology. Share infographics on LinkedIn with captions using your Category-of-One language. Each platform must link back to your primary entity and use identical author bios. Cross-platform presence creates semantic density—AI encounters you repeatedly, verifying your identity through pattern recognition.
Step 5: Apply The TBFA 8-Step Betweener OS
Use Betweener Engineering™ to maintain identity integrity as you scale: audit entity reality (what you actually do), audit AI perception (how AI classifies you), extract Domain A (structural truth), extract Domain B (narrative truth), create your Fusion Node (unified identity), build identity architecture (frameworks and definitions), distribute semantically (multi-modal content), and encode endurance (consistent reinforcement). This systematic approach ensures Visibility Footprint expansion strengthens—not dilutes—your Category-of-One Identity. Scale presence without losing clarity.
FAQs
What is YouTube’s first video and why does it matter for AI visibility?
On April 23, 2005, YouTube co-founder Jawed Karim uploaded “Me at the zoo,” an 18-second video filmed at the San Diego Zoo. It was the first video ever uploaded to YouTube. While the content itself was simple, it marked a fundamental shift in digital visibility: video became an accessible format for everyone, not just media companies. Before YouTube, video required expensive equipment, technical expertise, and distribution networks. YouTube democratized video, expanding what it meant to “exist online.” This matters for AI visibility because it revealed a core truth: format diversity creates visibility resilience. Today, AI systems do not rely on text alone—they synthesize signals from text, video, audio, images, and documents. YouTube proved that visibility is not just about content quality, but about format accessibility and machine-readable presence.
What is Visibility Footprint?
Visibility Footprint is the total digital surface area of machine-readable identity signals an entity maintains across platforms, formats, and semantic contexts. It is determined by four factors: format diversity (text, video, audio, visual), signal consistency (aligned identity across all formats), structural readiness (AI-parsable content), and cross-platform integration (coherent presence across ecosystems). A large Visibility Footprint means AI encounters your entity repeatedly across different contexts, increasing recall, citation, and recommendation probability. A small footprint limits AI’s understanding, leading to partial visibility or misclassification. Visibility Footprint is not content volume—it is surface area multiplied by consistency.
Why does multi-modal content increase AI visibility?
AI systems synthesize information across formats. ChatGPT references text and video transcripts. Perplexity blends articles, PDFs, and images. Google’s AI Overviews favor entities with rich media, structured data, and video presence. If your entity exists only in text, AI only encounters you in text-based queries. If you exist across text, video, audio, and visual formats, AI sees you across many more query contexts. Multi-modal presence also increases Machine Trust—AI verifies identity consistency across formats. When your website, YouTube channel, podcast, and visuals reinforce the same entity definition and positioning, AI recognizes a stable pattern. Single-format visibility is fragile. Multi-modal visibility is durable.
What is Signal Consistency and why does it matter?
Signal Consistency is the alignment of identity signals—entity definitions, framework names, terminology, and category positioning—across all formats and platforms. AI verifies entities through pattern recognition. If your website, videos, podcasts, and visuals describe you differently, AI detects contradiction rather than authority. Contradiction weakens Machine Trust. Consistency strengthens it. Signal Consistency requires deploying the same Fusion Node everywhere: the same entity definition, the same named methodologies, and the same categorical language. This is why identity architecture must precede distribution—visibility amplifies whatever identity structure already exists.
What is Structural Readiness?
Structural Readiness is the technical state of content being machine-readable and AI-parsable. Video without transcripts is invisible to text-based AI. Podcasts without show notes are invisible to search engines. Images without alt text are invisible to generative systems. PDFs without extractable text are invisible to answer engines. Structural Readiness converts content into AI-accessible signals through schema markup (JSON-LD), video transcripts, podcast RSS feeds, image alt tags, text-based PDFs, Open Graph metadata, and canonical URLs. Without Structural Readiness, content exists. With it, content becomes visibility.
What is a Fusion Node in Betweener Engineering?
A Fusion Node is the engineered identity created by unifying Domain A (structural truth: standards, processes, capabilities, proof) and Domain B (narrative truth: story, philosophy, meaning, and category definition) into a single, machine-readable entity. In Visibility Footprint terms, the Fusion Node is the identity that remains constant across all formats and platforms. Your website schema, YouTube descriptions, podcast bios, and visual captions should all express the same Fusion Node. Without it, multi-modal presence creates fragmentation. With it, multi-modal presence creates reinforcement—AI sees one coherent, verifiable identity everywhere.
What is Semantic Endurance and how does Visibility Footprint create it?
Semantic Endurance is the ability of an identity or concept to persist inside AI memory through repeated, consistent trust signals. Visibility Footprint creates Semantic Endurance by increasing semantic density—AI repeatedly encounters the same entity definition across formats, platforms, and contexts. This repetition stabilizes recall and attribution over time. AI systems constantly update their understanding of the world; entities without Semantic Endurance fade or drift. Entities with large, consistent Visibility Footprints remain stable, citable, and memorable. This is achieved through the Visibility Footprint Expansion Matrix: format diversity, signal consistency, structural readiness, and cross-platform integration.
What is the difference between AEO and GEO?
AEO (Answer Engine Optimization) focuses on structuring content so AI systems can parse, trust, and cite it. It emphasizes definitions, frameworks, and FAQ-style clarity. GEO (Generative Engine Optimization) focuses on recall—ensuring AI includes you in conversations, summaries, and recommendations. AEO is about being cited. GEO is about being remembered. Visibility Footprint supports both: AEO benefits from structural readiness and clear definitions, while GEO depends on signal consistency, entity clarity, and Semantic Endurance across platforms.
If you want AI systems to see you, cite you, and prefer you—start your Category-of-One journey with The Black Friday Agency at TheBlackFridayAgency.com.
Free Training
Free Training: TheBlackFridayAgency.com/Training.
Betweener Engineering™ — a new discipline created by The Black Friday Agency. Explore the discipline: BetweenerEngineering.com